Sections
Projects
jalleg
JVM binding for the Allegro game and multimedia library
jfxutils v1.0JavaFX Utilities - Zoom and Pan Charts and Pane Scaling
By now you should understand most of the basic principles of objects and how to use them. It's all nice to learn the syntax and the workings but now they need to be applied so they make our programming much more efficent.
This is where pointers show up in C++ as one of the most useful tools in programming. Before you may have wondered why anyone would want to use pointers unless they wanted to allocate large amounts of memory on and off during the program. This chapter will begin to explain this and will form a foundation on which to create an "engine" for your program, espically games.
In order to first start this, we need to know how to use objects with pointers. Since a class is used in C++ like any other variable, the pointer should intuitively follow this approach:
MyClass* classPtr; classPtr = new MyClass();
As with other variables, all of the same rules apply, the ampersand (&) to get the address, and the leading asterisk (*) to reach the actual data.
But what of the dot operator (.)? The dot operator requires data on the left side in order to access a function/variable in the class. You could do it this way:
(*classPtr).someFunction(); (*classPtr).someVariable = 15;
This statement works, but requires more typing. Luckily there is a shortcut for this, using the indirection operator (->). This operator works on a pointer to a class just like the dot operator. Note that if you use it to access a variable it returns the data of that variable and not a pointer to it:
classPtr->someFunction(); //Same as statements above classPtr->someVariable = 15;
Now that we know how to use these pointers, let put them to use in a linklist. All these little simply silly programs are probably starting to get boring. Well this is the first REAL, serious, programming application in the tutorial. I still use this today (check out the linklist library which is a fully developed class based off of what's to follow).
A linklist is like an array, but different -- to compare -- an array is contigous in memory, meaning it takes up one solid block of memory with no gaps in between. A linklist contains elements as well, but is like a chain, with each element connecting to the next, and therefore does not have to be as "rigid" as an array.
Why a linklist? Well imagine some of the drawbacks of an array. First of all you cannot resize an array. It must be of a fixed length. What if you have to add an element? You have to shift the rest of the array down, copying a lot of memory, and the same goes for deletion. In a linklist, in order to add an element, you simply "disconnect that chain," add the link, and reconnect -- just three steps, and the same for deletion. Below is a chart showing the disadvantages and advantages of both methods. Each one has its good and bad points and neither is worse or better than the other. Use the best method for the situtation. Don't worry if you don't understand all of it now as all topics are highlighted and it is meant for future reference.
|
Linked Lists vs Arrays |
|||
|
Linked Lists |
Arrays |
||
|
Advantages |
Disadvantages |
Advantages |
Disadvantages |
|
Easy to add/delete elements |
Cannot access an element in the list directly -- must follow chain |
Can access an element directly without speed penalty |
Hard to insert/delete elements |
|
Faster when sorting, adding, deleteing many elements with very little penalty |
Severe speed penalty for random access, sequential access only acceptable way |
No speed penalty for sequential or random access, faster access in general |
Severe penalty for adding and deleting elements increasing exponentially for large data types |
|
No speed penalty for dealing with larger objects |
Harder to program, easier to lose track of pointer and crash computer |
Easier to program |
Extreme penalty for dynamically resizing array |
| No speed penalty for resizing or shrinking size -- also no fixed size | Memory overhead (4 bytes per class) to store pointer to the next link | No memory overhead | Can hold objects of only one type |
| Can hold virtually unlimited numbers of objects of virtually unlimited types | Some sorting algorithms faster on fixed arrays | ||
| Fast and easy for alphabetical or comparative sorting | |||
How does this work? Well each element in a linked list keeps a pointer to the next element in the list, represented by this graphic:
![]()
First look at this imcompleted class:
class LinkedInteger {
private:
LinkedInteger* next; //pointer to the next element in the list
int data; //data in this link
}
You can see that the pointer is the key element to get this list to work. Below is a graphical representaion of a linked list (a standard array is also shown for comparison):
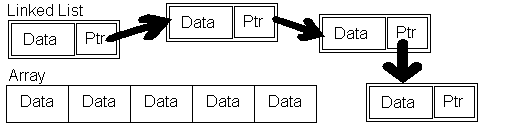
There are several ways to reference a linked list. The first method deals with creating an object directly (LinkedInteger start;) and adding elements to that. This has the disadvantage of not being able to have an empty list. The second method is is create a pointer to the first object in the list, or NULL if there are no objects (LinkedInteger* LiList;), which has the advantage of being able to store an empty list, but the disadvantage of only being able to hold one datatype. The third method is to create a class which manages a linked list. This has the advantage of data hiding (so you cannot access the links directly), and centralizes the code so that any bug in the list can exist in only one function in that class, rather than somewhere in your program when you directly access the list. It is this third method which will be explained here.
First let's create a "skeleton" for our new LinkList class. What operations do we want to perform on the list? Minimally, we need to be able to add, delete, and access elements in the list (using traverse functions). A length function may also be helpful, as well as an insertion function. What variables will we need? A pointer to the current element, a pointer to the previous element (for deletion and insertion), the pointer to the start (so we can start over at the beginning again).
class Person { //This is the data we will use
public:
void getData();
void showData();
private:
char* name;
int age;
char* occupation;
};
struct Link { //This is the fundamental unit of our list
Person* next;//next element
Person data; //actual data
};
class LinkList {//Acts as the interface to the program
public:
LinkList(); //Constructor
~LinkList(); //Destructor deallocates all used memory
void add(Person data); //Add an element to the start of the list
void insert(Person data);//Insert element before current
void delete(); //Delete current element
Person* getThis(); //Get curr element
void traverse(); //Go to next element
void startOver(); //Go back to the start
int len(); //Returns current list length
private:
Link* start; //beginning of list
Link* curr; //current element
Link* prev; //previous element
int length; //current list length
};
To use the LinkList, a user would first startOver();, and use getThis() to get the first element in the list, and use traverse() to proceed to the next. The user can modify/interact with the element through the pointer, and changes made to that data change also in the list. When getThis() returns NULL, the list is at the end. The method insert() at this point will add an element to the end (it adds an element before the current, and since it's one past the last, before the NULL is at the end). This makes the LinkList work like a stack, LIFO (Last in first out), so the first element is the last one added.
When in the middle of the list, the delete() method will delete the current element. The current element will become the next element (effectively calling a traverse() after the delete()).
Note that you did not need to know how this class worked to know how to use it -- such is the advantage of OOP.
The first thing we need to do is construct the LinkList. Since the list starts empty, start, prev, and curr will all be NULL, and length will be zero.
LinkList::LinkList() {
prev = curr = start = NULL;
length = 0;
}
Now to destruct the LinkList, we need to free all of the taken memory. But we don't know how the links work yet to do this, but, we know of a function in LinkList that will help, and that's called delete(). We can simply delete() all of the elements:
LinkList::~LinkList() {
startOver();
while(getThis() != NULL) {
delete(); //This also effectively advances
}
}
Also, since it really doesn't belong in any other section, I'll mention the len() method here. Actually it's too simple to mention. I'll leave it as an exercise to you to discover how that one works ;).
So how exactly do we work with these links? The first operation we need to perform on a linked list is adding elements. We have the option of creating at the start or the end of the list. But, the problem with adding at the end of the list is that we have to traverse it to get to the end, which is not very efficent. So, if we don't care about order, we can add objects up front very easily and quickly. If we did care about order, we would use the insert function which is comming later.
This is a picture of the add operation. The other links already exist, and the transparent arrow is the pointer about to be linked, and the lower left link is the new link:
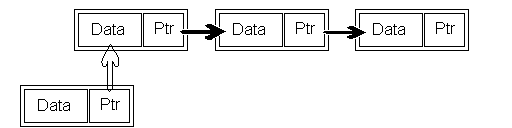
And below is the function to do this:
void LinkList::add(Person data) {
Link* newLink = new Link; //Allocate mem for a new link
newLink->next = start; //start will become second element
newLink->data = data; //copy data over
}
You may ask, "Well this is nice if there are already elements, but what if the list is empty?" Well, since the last link in the list's next pointer is NULL, if the list is empty, start will be NULL. NULL will be simply assigned to the next pointer of the link, making it the end link.
To insert links, we have to know the previous and next links, so this must happen at the current position in the list. This method is good for sorting lists, where you can search until you find an element greater, then insert() which adds the element before the currently selected one. Notice that the insert() code does not really alter the position in the list. Here is the code to do this:
void LinkList::insert(Person data) {
Link* newLink = new Link; //Allocate mem for a new link
newLink->next = curr; //current link becomes next
newLink->data = data; //copy data over
prev->next = newLink; //previous points to this now
prev = newLink; //this link is one before curr now
}
Traversing the list is easy. The current pointer becomes the next pointer of the current element (curr = curr->next;). It is suggested to also check to see if (curr == NULL), so the list isn't overrun:
void LinkList::traverse() {
if (curr != NULL) {
curr = curr->next;
}
}
To getThis(), simply return curr. See this linked list stuff isn't too hard.
Deleting is simple when you think about it in the same context as the other functions -- they really all follow the same theme. Well when you delete the previous will point to the next element, so that the route simply "skips" over this element. Then we can safely delete it. Unlike insert() though, this one will have to effectively advance the list since the current element is invalid.
void LinkList::delete() {
prev->next = curr->next; //"skip" over this element
delete curr; //remove this element
curr = prev->next; //"advance" to next element
}
Curr had to be assigned to prev->next rather than curr->next (as in the traverse method) because when we delete curr, its data is invalid and we can't reference it anymore. This is a common oversight, as this is not the intuitive order, but this order is required to get the list to work. Notice we could have chosen to fall back or go forward after the delete, but it makes much more sense to continue on with the list rather than backtracking.
The other functions are small and simple and are left as an exercise for you to do. In the next chapter we will cover a very valuable usage for the LinkList. If you want to use a LinkList or want to see a more complex and developed one, there is one available in the Archive.
Keep in mind this is still a work in progress!
This whole chapter comes from the concept presented by this code:
class BaseClass {
public:
void doStuff();
int data;
};
class DervClass : public BaseClass {
public:
void doStuff();
int moreData;
};
void main() {
DervClass obj1;
BaseClass obj2;
BaseClass* ptr1 = &obj1; //Assigning an DervClass to a BaseClass pointer!
}
This can seem pretty extreme, but if you think about it, this is totally workable. On a BaseClass*, you can use all of the functions available in BaseClass, which work on BaseClass variables. These functions and variables also exist in DervClass, being a class derived from BaseClass, and so the same things should work. This is because DervClass is really a "BaseClass and then some," and you can always in a sense "downgrade" your status.
When you call methods or access variables from the pointers, everything works as normal except for the fact that when you use the base pointer, you can only access things from the base class. For example, given a continuation of main() from above:
ptr1->doStuff(); //Calls BaseClass::doStuff(), NOT DervClass:dostuff()!
ptr1->moreData = 5; // NOT valid since moreData is in DervClass, and
//this is a BaseClass*
ptr1->data = 10; //Valid statement
In the next few lessons you will see how to overcome the problem presented by the last code, where the BaseClass::doStuff() was called when you probably wanted to call DervClass::doStuff().
Imagine this -- You have a whole bunch of different types of objects in your program, say, many different types of people, but they all have only slightly differing propertities. Because of this, you would make it simpler and have all of the classes share the same code (Person class) and where there are different properties, create a dervied class, like Student. Now imagine they have some sort of routine that you must call on all of them they they have in common, such as display(), which prints a message to the console telling themselves about them "My name is <name> and I am a Student. I'm <age> years old." or something similar to that.
Now that you have the basic design set up, you need to keep track of a large array of people. The only problem with an array is that it can only hold only one type. Based on the previous section with assigning pointers of derived classes to base class pointer variables, you could make the array:
Person* array[512]; //An array of pointers
There is one major problem with this. You have to know the maximum number of people to store. A better method would be to use the linked list above, and modifying it so that it stores Person* rather than Person data. That way we can just declare a LinkList and add and delete people nearly as quickly as the array. This is also assuming that we only need to access people sequentially (from start to end and perform operations as you go along). If for some reason we wanted to access people randomly or by some ID number, an array may have to do, or a Vector-type class which is an array which expands and contracts itself as needed (Vectors are not discussed in this tutorial). You can refer back to the chart dealing with LinkLists vs Arrays to see when to pick one over the other.
So let's examine the code for the classes before we go any further. The Person class is the basic functions which apply to any person. All of the implementation (code) of the class except for one method is not completed because it is unnessacary in this case. The routines are simple and you can fill in the code as an exercise.
class Person {
public:
Person(char* name, int age, char* address);
//copies strings
virtual ~Person();
char* getName();
int getAge();
char* getAddress();
//set functions copy strings
char* setName();
int setAge();
char* setAddress();
virtual void display();
private:
char* name;
int age;
char* address;
};
class Student : public Person {
public:
Student(char* name, int age, char* address, char* school);
//copies strings
virtual ~Student();
void display();
private:
char* school;
};
The reserved word virtual is the main concept presented by this code. On methods besides the destructor, this means that the method can be overridden by an inherited class when the method is called on the base pointer. This can sound confusing at first since the previous lessons have already shown this is possible. But with virtual functions the point is that you do not need to know which class it came from! Observe the following code:
//The usual way:
Person man("Bob", 35, "15th S Pine St");
Student woman("Jill", 19, "n/a -- dormatory", "RIT");
man.display(); //This is valid, called Person::display()
woman.display(); //calls Student::display()
//With virtual methods:
Person* baseptr = man;
baseptr->display(); //calls Person::display()
baseptr = woman; //Can assign Student* to Person*
baseptr->display(); //Calls Student::display();
Using the virtual keyword we overcame the problem we had in the first lesson for this chapter. Even when the pointer loses its identity we can still override functions in the derived class. Note that even still, the method must exist in the base class in order to call it -- it is just simply virtual says it should look to see if there is an override.
You may also have noticed that the destructors are virtual as well. What is this supposed to mean? Well when you use the delete operator, and call it on the base pointer, it would call the destructor for the base class only without destructing the derived class. With the virtual keyword, the compiler will look for the destructor in the child class.
In other words: if you have any virtual functions in a class, or you will be (or think you might be) using a class through a pointer to one of its parent classes as we have done in this chapter, you need to make the destructor virtual. If you do not the class will not be destroyed properly and the correct destructor will not be called, potentially causing memory leaks and other errors.